
Alla fine del 2023, tra tutte le novità legate all'Intelligenza Artificiale, il fatto che Apple si stia finalmente facendo avanti è probabilmente il più importante di tutti.
Sebbene sia stato rilasciato a ottobre, un modello Apple chiamato Ferret ha recentemente attirato l'attenzione dei media.
Non solo è il primo del suo genere, ma batte anche ChatGPT-Vision in diverse attività, offrendo nuovi indizi su ciò che Apple potrebbe preparare per il mondo nel 2024.
L'Importanza di Fare le Cose Bene
Tra tutti i problemi che si possono affrontare con un Modello Linguistico, le allucinazioni sono solitamente le prime.
I Large Language Models (LLM) sono essenzialmente predittori di parole stocastici, e ogni risposta che forniscono ha un certo livello di imprevedibilità.
Per questo, quando si utilizzano questi modelli, è fondamentale fornire loro contesto rilevante nel prompt, in modo che la risposta non sia completamente inventata.
Questo processo, chiamato "apprendimento in contesto", fornisce il contesto rilevante per la risposta in tempo reale.
Ferret: Il Nuovo Modello Linguistico di Apple
Apple ha creato un modello linguistico multimodale (LLM) open source chiamato Ferret. Questo modello è in grado di comprendere e produrre testo, immagini, suoni e video, superando in prestazioni GPT-4 di OpenAI, il modello linguistico più avanzato fino ad ora.
Per addestrare Ferret, Apple ha utilizzato 8 potenti GPU Nvidia A100, con una capacità di 80 GB di RAM HBM2e, raggiungendo prestazioni fino a 312 TeraFLOPS. Questo modello si distingue nella descrizione dettagliata di parti delle immagini, riducendo gli errori.
Il Futuro di Ferret sugli Smartphone
Sebbene Apple sia solo all'inizio dell'avventura nell'AI generativa con Ferret, l'obiettivo è renderlo compatibile con gli smartphone. Mentre GPT-4 di OpenAI ha più di 1 trilione di parametri, attualmente gli smartphone possono gestire solo LLM con circa 10 miliardi di parametri.
Per risolvere questo problema, i ricercatori Apple stanno esplorando l'utilizzo della memoria flash integrata dello smartphone oltre alla RAM. Si prevede che l'iPhone 16 potrebbe includere un assistente AI basato su Ferret.
Approfondimento Tecnico con Ferret-Bench e GRIT Dataset
Il modello Ferret utilizza una rappresentazione ibrida della regione e un campionatore visuale consapevole dello spazio, consentendo un riferimento e ancoraggio finemente dettagliati in un contesto multimodale. Il dataset GRIT, con oltre 1,1 milioni di campioni, è cruciale per il miglioramento del modello.
Per chi desidera esplorare ulteriormente, il modello Ferret è disponibile su GitHub: Ferret su GitHub.
Conclusione: Il Dominio di Apple nell'AI Generativa
Apple sta dimostrando di essere una forza da non sottovalutare nel campo dell'Intelligenza Artificiale con il suo modello Ferret. La sua capacità di superare i concorrenti e la visione di renderlo accessibile sugli smartphone indicano un futuro promettente nel mondo dell'AI.
Licenza d'uso
La licenza fornita da Apple per il software descritto è una licenza di utilizzo, ma non rientra completamente nella definizione tradizionale di "open source". La licenza è nota come la "Apple Open Source License" o "APSL" e ha alcune caratteristiche specifiche.
Di seguito sono riportati i principali punti della licenza:
- Uso e Accettazione dei Termini: L'uso, l'installazione, la modifica o la ridistribuzione del software di Apple costituisce un'accettazione dei termini di licenza.
- Licenza Personale e Non Esclusiva: Apple concede all'utente una licenza personale e non esclusiva per l'utilizzo, la riproduzione, la modifica e la ridistribuzione del software, sia in forma sorgente che binaria.
- Obbligo di Conservare Notifiche: Se si ridistribuisce il software di Apple senza apportare modifiche, è necessario conservare la notifica di copyright e le dichiarazioni di non responsabilità specificate nella licenza.
- Vietato l'Utilizzo di Marchi e Loghi: Non è consentito utilizzare i nomi, i marchi, i marchi di servizio o i loghi di Apple per promuovere prodotti derivati dal software senza specifica autorizzazione scritta.
- Nessuna Garanzia: Apple fornisce il software "AS IS" e declina ogni tipo di garanzia, sia espressa che implicita, inclusa la mancanza di violazione di diritti, commerciabilità e idoneità a uno scopo particolare.
- Limitazione di Responsabilità: Apple non sarà responsabile per danni speciali, indiretti, incidentali o consequenziali derivanti dall'uso, la riproduzione, la modifica e/o la distribuzione del software.
- Limitazioni sulle Azioni Legali: La licenza specifica che, in caso di azioni legali contro Apple, l'utente non può richiedere danni o richiedere il divieto dell'uso del software.
In sintesi, la licenza di Apple per questo software è aperta nel senso che consente agli utenti di utilizzare, modificare e ridistribuire il software, ma presenta alcune restrizioni, principalmente riguardo all'uso di marchi e loghi di Apple e limitazioni della responsabilità. La licenza è incentrata sulla responsabilità dell'utente e sull'accettazione delle condizioni specificate da Apple.
Il paper "Ferret: Refer and Ground Anything Anywhere at Any Granularity" presenta Ferret come un nuovo Multimodal Large Language Model (MLLM) progettato per comprendere riferimenti spaziali di qualsiasi forma o granularità all'interno di un'immagine e ancorare con precisione descrizioni con un vocabolario aperto.
Il punto chiave del paper è l'introduzione di una rappresentazione ibrida della regione, una novità potente che integra coordinate discrete e caratteristiche continue per rappresentare congiuntamente una regione nell'immagine. Questo approccio consente a Ferret di accettare input di regioni diversificate, come punti, bounding boxes e forme libere.
Per estrarre le caratteristiche continue delle regioni versatili, il paper propone l'uso di un campionatore visuale consapevole dello spazio, in grado di gestire varie sparsità attraverso diverse forme. Questo componente aggiuntivo contribuisce a migliorare le capacità desiderate di Ferret.
Inoltre, il paper menziona la creazione di un dataset denominato GRIT, che è fondamentale per il perfezionamento del modello. GRIT è un dataset completo di istruzioni per il riferimento e l'ancoraggio, che include 1,1 milioni di campioni con una conoscenza spaziale gerarchica ricca. Di particolare rilievo sono i 95.000 dati difficili negativi inclusi nel dataset per promuovere la robustezza del modello.
Il modello risultante non solo ottiene prestazioni superiori nelle attività classiche di riferimento e ancoraggio, ma supera notevolmente gli altri MLLM esistenti nelle conversazioni multimodali basate su regioni e richieste di localizzazione. Le valutazioni effettuate indicano anche un miglioramento significativo nella capacità di descrivere dettagli delle immagini e un notevole alleviamento delle allucinazioni di oggetti.
Il paper conclude annunciando che il codice e i dati saranno resi disponibili all'URL specificato. Il focus del lavoro è chiaramente sulla creazione di un modello linguistico multimodale avanzato e robusto, in grado di affrontare sfide specifiche di riferimento e ancoraggio nello spazio all'interno di un contesto multimodale.
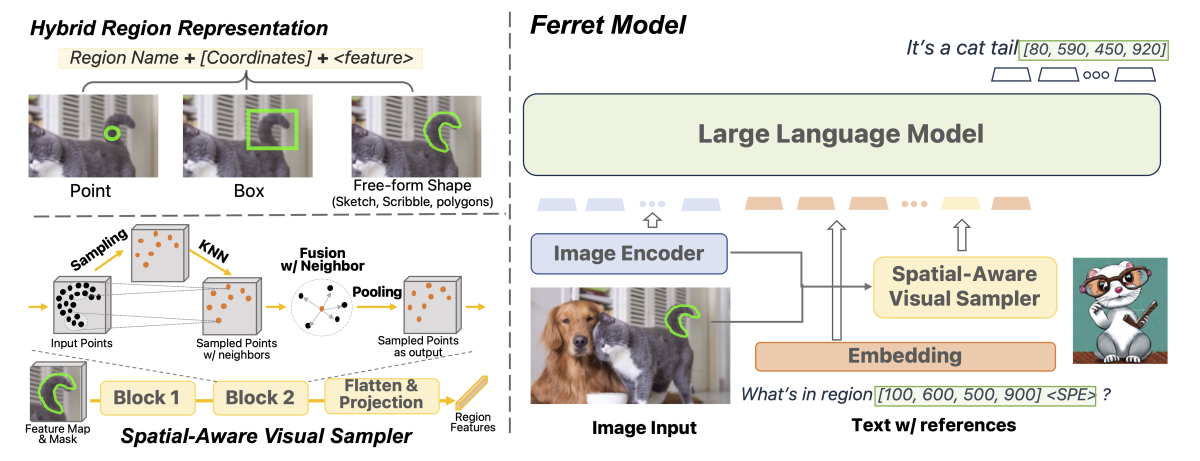
L'Overview fornisce una sintesi chiara delle principali contribuzioni del lavoro presentato nel paper "Ferret: Refer and Ground Anything Anywhere at Any Granularity". Qui di seguito spiego ogni punto:
Ferret Model - Rappresentazione Ibrida della Regione + Campionatore Visuale Consapevole dello Spazio:
- Contributo Chiave: Il modello Ferret introduce una rappresentazione ibrida della regione, che combina coordinate discrete e caratteristiche continue per rappresentare efficacemente una regione in un'immagine. Inoltre, viene proposto un campionatore visuale consapevole dello spazio, progettato per gestire varie sparsità tra diverse forme. Questa combinazione consente a Ferret di affrontare riferimenti spaziali di qualsiasi forma o granularità, consentendo una descrizione dettagliata e aperta nel vocabolario all'interno di un Multimodal Large Language Model (MLLM).
GRIT Dataset (~1.1M) - Dataset di Istruzioni per l'Ancoraggio e il Riferimento a Terra:
- Contributo Chiave: Viene presentato il GRIT Dataset, un dataset su larga scala contenente istruzioni per l'ancoraggio e il riferimento a terra. Con circa 1,1 milioni di campioni, questo dataset è caratterizzato dalla sua struttura gerarchica, fornendo una conoscenza spaziale dettagliata. Inoltre, sono inclusi 95.000 dati difficili negativi nel dataset per promuovere la robustezza del modello. Il GRIT Dataset svolge un ruolo fondamentale nel perfezionamento del modello Ferret.
Ferret-Bench - Benchmark di Valutazione Multimodale:
- Contributo Chiave: Ferret-Bench è presentato come un benchmark di valutazione multimodale progettato per testare il modello Ferret su diverse capacità. Questo benchmark richiede valutazioni su riferimento/ancoraggio, semantica, conoscenza e ragionamento. La creazione di Ferret-Bench è un contributo essenziale per valutare in modo completo le prestazioni del modello Ferret in contesti multimodali.
Release:
- Contributo Chiave: Il paper menziona una release, indicando che il codice sorgente e i dati saranno resi disponibili. Questo è importante per garantire la trasparenza, la riproducibilità e la condivisione del lavoro con la comunità scientifica e gli sviluppatori interessati.
In conclusione, questa Overview fornisce una visione chiara delle innovazioni chiave presentate nel paper, evidenziando il modello Ferret, il dataset GRIT e il benchmark di valutazione Ferret-Bench come contributi significativi nel campo dell'ancoraggio e del riferimento spaziale all'interno di modelli linguistici multimodali.
#AppleAI #Ferret #IntelligenzaArtificiale #ChatGPT #Tecnologia
Fonti:
Glossario
- Multimodal Large Language Model (MLLM): Un modello linguistico multimodale che può comprendere e generare testo, immagini, suoni e video. Nel contesto del paper, Ferret è un esempio di MLLM.
- Rappresentazione Ibrida della Regione: Un'approccio che integra coordinate discrete e caratteristiche continue per rappresentare una regione in un'immagine. Nel contesto del paper, il modello Ferret utilizza questa rappresentazione per comprendere riferimenti spaziali.
- Campionatore Visuale Consapevole dello Spazio: Un componente che estrae caratteristiche continue di regioni versatili in un'immagine, con una consapevolezza dello spazio per gestire varie sparsità tra diverse forme.
- GRIT Dataset: Un dataset di istruzioni per l'ancoraggio e il riferimento a terra. Contiene circa 1,1 milioni di campioni e presenta una struttura gerarchica, fornendo una conoscenza spaziale dettagliata.
- Dati Difficili Negativi: Nel contesto del GRIT Dataset, si riferisce a campioni che presentano sfide particolari o condizioni difficili per promuovere la robustezza del modello durante l'addestramento e la valutazione.
- Benchmark di Valutazione Multimodale (Ferret-Bench): Un insieme di criteri e metriche utilizzati per valutare le prestazioni di un modello in diverse capacità, inclusi riferimento/ancoraggio, semantica, conoscenza e ragionamento.
- Release: La distribuzione pubblica del codice sorgente e dei dati correlati al lavoro. Indica che questi saranno resi disponibili per l'accesso e l'utilizzo da parte di altri.
- MLLM (Multimodal Large Language Model): Un modello linguistico avanzato capace di comprendere e generare testo, immagini, suoni e video.
- Hybrid Region Representation: Una rappresentazione che combina coordinate discrete e caratteristiche continue per descrivere una regione in un'immagine.
- Spatial-aware Visual Sampler: Un componente che estrae caratteristiche continue da regioni variegate in un'immagine, con consapevolezza dello spazio per gestire varie sparsità tra forme diverse.
- GRIT Dataset (Ground-and-Refer Instruction Tuning Dataset): Un dataset di istruzioni per l'ancoraggio e il riferimento a terra, caratterizzato da una struttura gerarchica e contenente circa 1,1 milioni di campioni.
- Hard Negative Data: Campioni nel GRIT Dataset che presentano sfide particolari o condizioni difficili per promuovere la robustezza del modello.
- Ferret-Bench: Un benchmark di valutazione multimodale che include criteri per valutare diverse capacità, come riferimento/ancoraggio, semantica, conoscenza e ragionamento.
- Release: La distribuzione pubblica del codice sorgente e dei dati correlati al lavoro, resi disponibili per l'accesso e l'utilizzo da parte di altri.
- Ancoraggio: Un processo in cui un modello linguistico associa concetti o oggetti presenti in un'immagine a parole specifiche o descrizioni.
- Riferimento a Terra: Il collegamento di descrizioni di testo a regioni specifiche di un'immagine in modo dettagliato.
- LLM (Large Language Model): Modello linguistico di grandi dimensioni.
- GPU (Graphics Processing Unit): Unità di elaborazione grafica, utilizzata per il calcolo parallelo.
- RAM (Random Access Memory): Memoria ad accesso casuale, utilizzata per archiviare dati temporanei.
- API (Application Programming Interface): Interfaccia di programmazione delle applicazioni, che consente a diverse applicazioni di comunicare tra loro.
- URL (Uniform Resource Locator): Indirizzo Web standard utilizzato per accedere a risorse su Internet.
- DOI (Digital Object Identifier): Identificatore univoco per un documento digitale.
- AppleAI: si riferisce all'iniziativa di Apple nel campo dell'Intelligenza Artificiale (IA) e, in particolare, al suo modello linguistico multimodale chiamato Ferret. Lanciato nel 2023, Ferret è un Large Language Model (LLM) open source sviluppato da Apple, progettato per comprendere e generare testo, immagini, suoni e video.a












